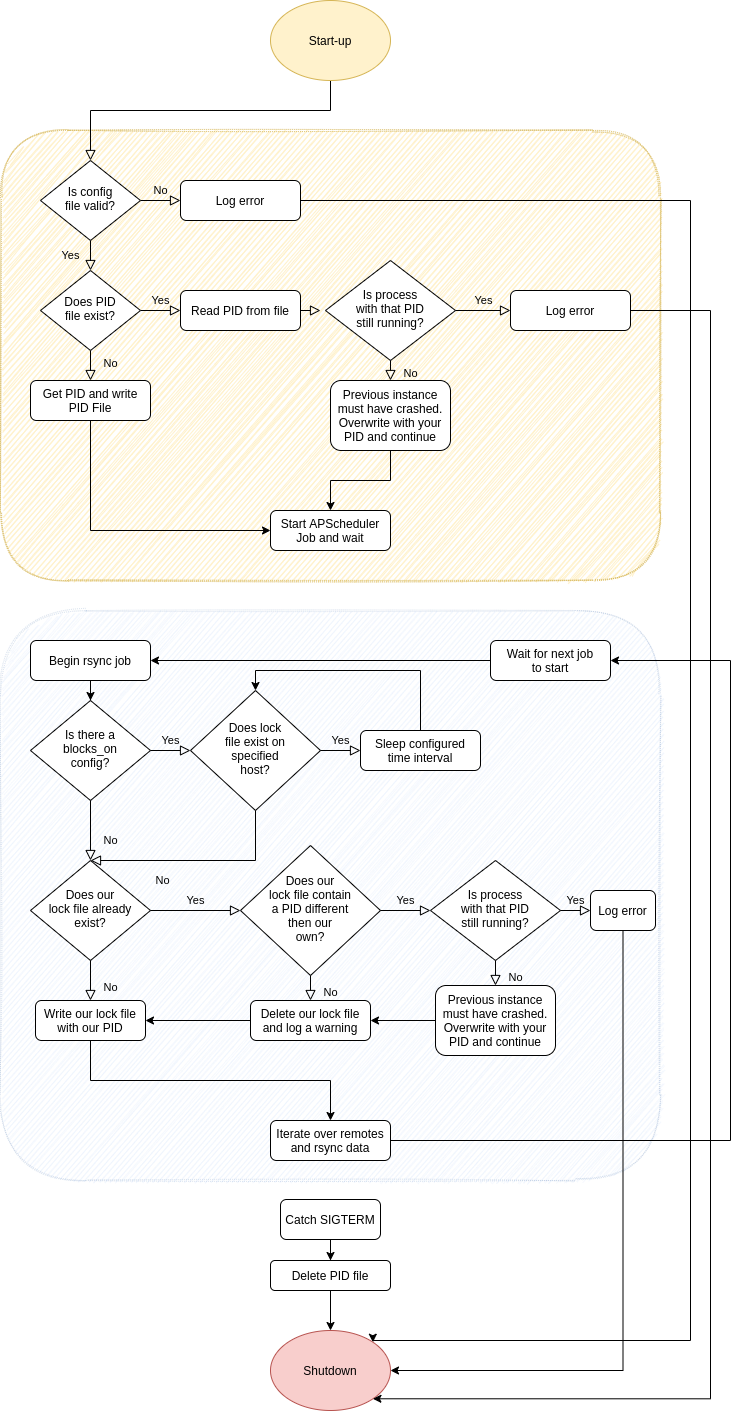
Following is the design for the backupmanager.
The first version will focus solely on rsyncing data. The roadmap includes adding the ability to generate incremental tarballs and manage aging them out over time.
It will run as a systemd managed service installed directly on the host on which you want to backup data from to N number of remote hosts. It will be a Python 3.7 program that will run scheduled jobs via APScheduler cron jobs, without any dependency on cron jobs run on the host.
It will feature the ability to chain together multiple instances of it across multiple hosts to manage the synchronization of various asynchronous rsync operations.
For example; you have a desktop (local_desktop) on which you have your music, photos, email, and other files that you want backed up. Further, you have a backup server (backup_a) at the same location as the aforementioned desktop to which you rsync data from a number of different directories on a daily basis. Further, you have another backup server at a remote location (backup_b) to which you rsync data across the Internet from backup_a every four days.
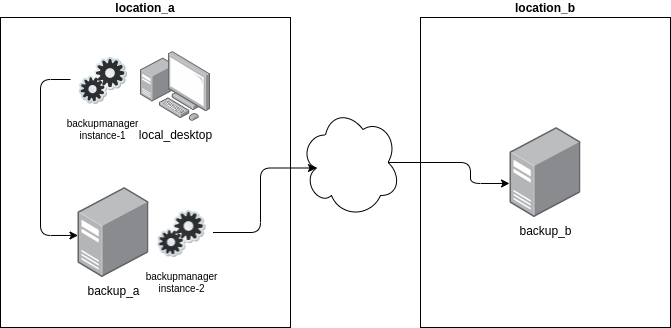
In this scenario there are two instances of the backupmanager running. The first on the local_desktop and the second on backup_a. A backupmanager instance can be configured to block on another instance of the backupmanager so as not to overwrite data that is already being rsynced.
Continuing with this example; when backupmanager instance-2 is running (rsyncing data to backup_b), it will write a lock file in a known location. backupmanager instance-1 will be configured to look for the aforementioned lock file when it runs its regularly scheduled rsync job. If backupmanager instance-1 finds the lock file when it starts its rsync job it will wait a configurable amount of time before re-checking for the existence of the lock file. It will continue checking until it no longer finds the lock file and will then proceed rsyncing its data from local_desktop to backup_a.
Configuration File
# Schedule on which we want these jobs to run. Uses the same
# syntax as a standard Linux cron job.
cron_schedule: '* * * * *'
# Directory into which we will write a pid file. This will
# prevent two instances of the application running at the same
# time. Default is /var/run/backupmanage
pid_file_dir: /var/run/backupmanager
# List of rsync jobs. Each job will contain a list of source
# and destination dirs/files to be rsynced.
jobs:
- id: local_rsync
type: local
# List of source:dest dirs/files to rsync
syncs:
- source: /source/path
dest: /path/on/local/host
opts:
- "-av"
- "--delete"
- "--exclude '.cache'"
- "--exclude 'Downloads'"
- id: local_desktop_to_backup_a
type: remote
# The user that we will use to make the rsync connection to
# the dest host
user: root
host: backup_a.example.com
# Optional overriding SSH port
port: 22000
# Optional path to a private SSH key to use to authenticate
# with the remote host.
private_ssh_key: /var/tmp/some-private-ssh-key
# Definitions for any arbitrary number of lock files that
# this process will create and manage on either the
# localhost or any remote. The lockfiles will indicate that
# this process is running this rsync job.
lock_files:
- type: local
path: /var/run/backupmanager/local_desktop_to_backup_a
- type: remote
host: backup_a.example.com
user: root
# Optional overriding SSH port
port: 22000
# Optional path to a private SSH key to use to authenticate
# with the remote host.
private_ssh_key: /var/tmp/some-private-ssh-key
path: /var/run/backupmanager/local_desktop_to_backup_a
# Optional configuration that tells the backup manager that
# it will block on a lockfile on the remote host. If any of
# the files exist the job will wait to start.
blocks_on:
- type: remote
# The user name that we will use to connect to the
# remote host
user: root
host: backup_a.example.com
# Optional overriding SSH port
port: 22000
# Optional path to a private SSH key to use to authenticate
# with the remote host.
private_ssh_key: /var/tmp/some-private-ssh-key
lock_file_path: /var/run/some-lock-file
# Amount of time in seconds to wait to retry
wait_time: 300
# There can also be any number of other lock files on
# the localhost on which we will also block
- type: local
lock_file_path: /lockfile/on/localhost
wait_time: 300
# List of source:dest dirs/files to rsync
syncs:
- source: /source/path
dest: /path/on/remote/host
opts:
- "-av"
- "--delete"
- "--exclude '.cache'"
- "--exclude 'Downloads'"
Flow Diagram